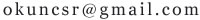select testid,count(1) from testtable group by testid having count(1)>1
count(1)就是重复在数量
如何查询重复的数据
select 字段1,字段2,count(*) from 表名 group by 字段1,字段2 having count(*) > 1
PS:将上面的>号改为=号就可以查询出没有重复的数据了。
Oracle删除重复数据的SQL(删除所有):
删除重复数据的基本结构写法:
想要删除这些重复的数据,可以使用下面语句进行删除
delete from 表名 a where 字段1,字段2 in
(select 字段1,字段2,count(*) from 表名 group by 字段1,字段2 having count(*) > 1)
上面的SQL注意:语句非常简单,就是将查询到的数据删除掉。不过这种删除执行的效率非常低,对于大数据量来说,可能会将数据库吊死。
建议先将查询到的重复的数据插入到一个临时表中,然后对进行删除,这样,执行删除的时候就不用再进行一次查询了。如下:
CREATE TABLE 临时表 AS (select 字段1,字段2,count(*) from 表名 group by 字段1,字段2 having count(*) > 1)
上面这句话就是建立了临时表,并将查询到的数据插入其中。
下面就可以进行这样的删除操作了:
delete from 表名 a where 字段1,字段2 in (select 字段1,字段2 from 临时表);
温馨提示:内容为网友见解,仅供参考
无其他回答
相似回答